Let’s say you have 1,000 letters to stamp and mail.
You could hire 1,000 people at once — but they’d all fight over the stamp, crash into each other, and get less done than 5 people working steadily through a pile. That second option — a small fixed team working through a shared queue — is a worker pool.
In this post we’ll build one in Go from scratch. No prior concurrency experience needed. We’ll use a real problem throughout: checking whether a list of URLs is up or down.
First: what is a goroutine?
A goroutine is Go’s way of doing something in the background. When you write go doSomething(), Go starts it and immediately moves on — it doesn’t stop and wait.
go checkURL("https://example.com") // starts in the background
go checkURL("https://google.com") // also starts, right away
// both are running at the same time nowThis is called concurrency — multiple things in flight at once. It’s one of Go’s best features. It’s also easy to misuse, which is exactly how we’ll motivate the worker pool.
The obvious first attempt
You have 1,000 URLs to check. Goroutines look like the perfect tool:
for _, url := range urls {
go checkURL(url)
}This starts 1,000 goroutines at the exact same moment. All of them hit the network at once. All of them want CPU time at once. It compiles, it runs — and then things start timing out and crashing.
Goroutines are lightweight, but they’re not free. Too many at once and you get:
- Slow responses — everyone is competing for the same resources
- Crashed connections — the network gets overwhelmed
- A program that’s hard to control or debug
You: "Everyone go RIGHT NOW"
1000 goroutines: 🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃
🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃🏃
... 960 more ...
Network: 😰 (can only handle so much at once)What you actually want is concurrency with a ceiling — say, only 5 things running at the same time, no matter how many tasks you have. That’s the worker pool.
How the worker pool works
Picture a conveyor belt with a small team of workers standing beside it.
Jobs go onto the belt. Each free worker picks up the next job, does the work, and comes back for more. If all workers are busy, new jobs just wait on the belt. No chaos — steady, controlled throughput.
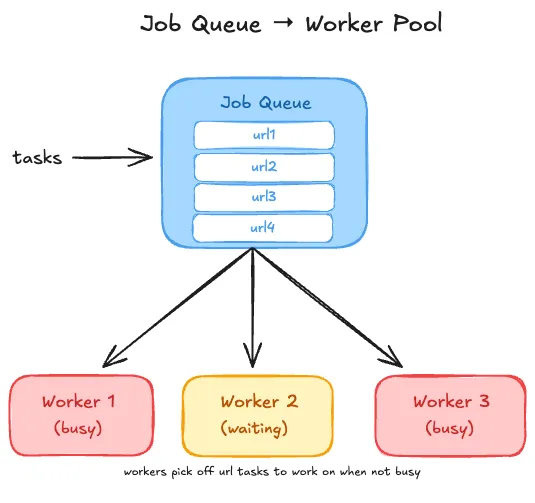
3 workers, 4 URLs in the queue — only 3 get checked at once. The fourth waits. When a worker finishes, it picks it up. You get speed and control.
The queue is a channel
Before we write any pool code, you need to know about channels — because the job queue in our pool is one.
A channel is a tube. You drop items in one end, pull them out the other.
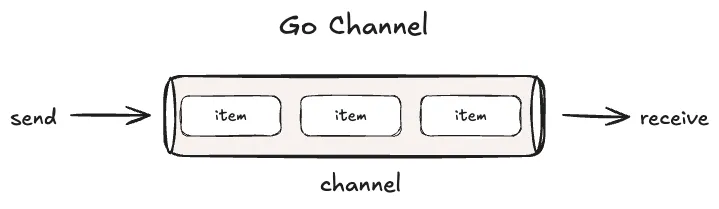
What makes channels great here: multiple goroutines can safely read and write to a channel at the same time. No race conditions, no locks needed — Go handles the coordination for you.
In our pool: the main program sends URLs into the channel. Workers pull them out.
Building it, piece by piece
Step 1: define the struct
type Pool struct {
numOfWorkers int
jobs chan string
wg sync.WaitGroup
}Three fields — and it’s worth naming what each one actually does:
numOfWorkers— your ceiling. You decide this number.jobs— the channel. The shared conveyor belt between the main program and the workers.wg— a WaitGroup. Think of it as a scoreboard: goes up when a worker starts, down when it finishes. When it hits zero, everyone is done.
Step 2: create the pool
func NewPool(numberOfWorkers int) *Pool {
return &Pool{
numOfWorkers: numberOfWorkers,
jobs: make(chan string, 10),
}
}make(chan string, 10) creates a channel with a buffer of 10. That means you can drop up to 10 jobs in before anyone needs to be reading them — like a waiting room with 10 seats. Once the seats are full, the next arrival waits at the door.
Step 3: write the worker
This is where the pattern actually lives.
func (p *Pool) worker() {
for job := range p.jobs {
result := checkURL(job)
fmt.Println(result)
}
}for job := range p.jobs sits and waits until a job appears in the channel. When one does, the worker grabs it, does the work, and loops back to wait. When the channel is closed and empty, the loop ends and the worker exits cleanly.
start
│
▼
wait for job ◄──────────────────────────┐
│ │
│ job arrives │
▼ │
do the work │
│ │
▼ │
handle result ───────────────────────────┘
│
│ channel closed AND empty
▼
done, exitStep 4: start the workers
func (p *Pool) Start() {
for range p.numOfWorkers {
p.wg.Go(func() {
p.worker()
})
}
}p.wg.Go(...) launches a goroutine and adds 1 to the scoreboard in one call. Do this numOfWorkers times and you have N workers sitting and waiting for jobs.
wg.Gowas added in Go 1.25. In earlier versions you’d writewg.Add(1)thengo func() { defer wg.Done(); p.worker() }(). Same idea, more ceremony.
Step 5: send jobs in
func (p *Pool) Submit(job string) {
p.jobs <- job
}The <- sends a URL into the channel. If all 10 buffer slots are full, Submit pauses and waits until a worker frees one up. This is a feature — it naturally stops you from queuing infinite work ahead of the workers.
Step 6: stop cleanly
Most examples skip this. Don’t.
func (p *Pool) Stop(ctx context.Context) error {
close(p.jobs)
done := make(chan struct{})
go func() {
p.wg.Wait()
close(done)
}()
select {
case <-done:
return nil
case <-ctx.Done():
return fmt.Errorf("pool stop: %w", ctx.Err())
}
}Three things happen here:
close(p.jobs)— signals “nothing more is coming.” Workers drain what’s left in the queue, theirrangeloop ends, and they exit.p.wg.Wait()— waits for the scoreboard to hit zero, meaning every worker has actually finished.- The
select— you pass in a context with a timeout. Workers done in time? Clean exit. Something hanging (a URL that never responds)? You get an error back instead of waiting forever.
close(jobs)
│
▼
workers finish current job
drain remaining jobs in queue
workers exit
│
▼
wg.Wait() returns (scoreboard = 0)
│
▼
done ✓The full working example
package main
import (
"context"
"fmt"
"net/http"
"sync"
"time"
)
type Pool struct {
numOfWorkers int
jobs chan string
wg sync.WaitGroup
}
func NewPool(numberOfWorkers int) *Pool {
return &Pool{
numOfWorkers: numberOfWorkers,
jobs: make(chan string, 10),
}
}
func (p *Pool) Start() {
for range p.numOfWorkers {
p.wg.Go(func() {
p.worker()
})
}
}
func (p *Pool) Submit(job string) {
p.jobs <- job
}
func (p *Pool) Stop(ctx context.Context) error {
close(p.jobs)
done := make(chan struct{})
go func() {
p.wg.Wait()
close(done)
}()
select {
case <-done:
return nil
case <-ctx.Done():
return fmt.Errorf("pool stop: %w", ctx.Err())
}
}
func (p *Pool) worker() {
for url := range p.jobs {
status := checkURL(url)
fmt.Printf("%s → %s\n", url, status)
}
}
func checkURL(url string) string {
resp, err := http.Get(url)
if err != nil {
return "DOWN"
}
defer resp.Body.Close()
if resp.StatusCode == 200 {
return "UP"
}
return fmt.Sprintf("UNKNOWN (%d)", resp.StatusCode)
}
func main() {
urls := []string{
"https://example.com",
"https://google.com",
"https://github.com",
"https://definitely-not-a-real-site-xyz.com",
"https://go.dev",
}
pool := NewPool(3)
pool.Start()
for _, url := range urls {
pool.Submit(url)
}
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
if err := pool.Stop(ctx); err != nil {
fmt.Printf("shutdown error: %v\n", err)
}
}Run it and you’ll see 3 URLs resolve in roughly the same breath, then the remaining 2 after. That staggered output is the pool working — 3 workers, never more than 3 at once.
Three mistakes people make (including me)
1. Forgetting to close the channel
If you never call close(p.jobs), workers sit in their range loop forever, waiting for a job that will never arrive. wg.Wait() also waits forever. The program hangs silently on shutdown with no error, no clue why.
Always close the channel once you’re done submitting work.
2. Closing the channel while still sending to it
This one panics immediately, which at least tells you something went wrong:
panic: send on closed channelIt happens when Stop closes the channel while something is still calling Submit. The fix is ordering — stop whatever is feeding the pool before you close:
WRONG order: RIGHT order:
close(jobs) stop the feeder first
submit(job) → PANIC close(jobs)
wg.Wait()3. Buffer too small
A buffer of 0 means every Submit blocks until a worker is ready to pick it up — your loop can’t get ahead of the workers at all. You’ve accidentally made the whole thing sequential.
A buffer of 10 lets the submitting loop run freely ahead of the workers. Rule of thumb: buffer size ≈ one full batch of work.
When to reach for a worker pool
A worker pool is the right tool when:
- You have a list of tasks to work through — URLs, files, records, messages
- You want a hard limit on how many run at the same time
- The tasks are independent — task 3 doesn’t need the result of task 2
- You need a clean shutdown — finish what’s in progress, don’t abandon it halfway
If you only have a handful of tasks, just launch goroutines directly. The pool earns its keep when you have hundreds or thousands of tasks and you need the control.
Further reading
- Go sync package docs
- Go channel tour — interactive, takes 10 minutes
- Concurrency in Go by Katherine Cox-Buday — chapters 3 and 4 if you want to go deeper